来源 | l2fees.info
从 2020 年起,以太坊的扩容路线图已经以 “rollup” 为方向:rollup 是一种使用证明(零知识证明或是 optimistic 欺诈证明)来继承以太坊安全性的独立执行环境。
在经过多年的开发后,rollup 最终被部署到以太坊上并且逐渐得到采用。这项技术的佼佼者 Arbitrum 的 optimistic rollup 已上线近一年,它的桥接上存着价值 27 亿美元以上的资产,而紧随其后的是 Optimism。我们已经能看到如 Loopring 和 dYdX 等应用专用型零知识证明 rollup 有了大量的采用,并且有很多具有竞争性的通用型零知识证明 rollup 会在接下来几个月发布。
尽管 rollup 领域扩容进展十分快速,但有人就费用还是过于高昂表达了担忧。
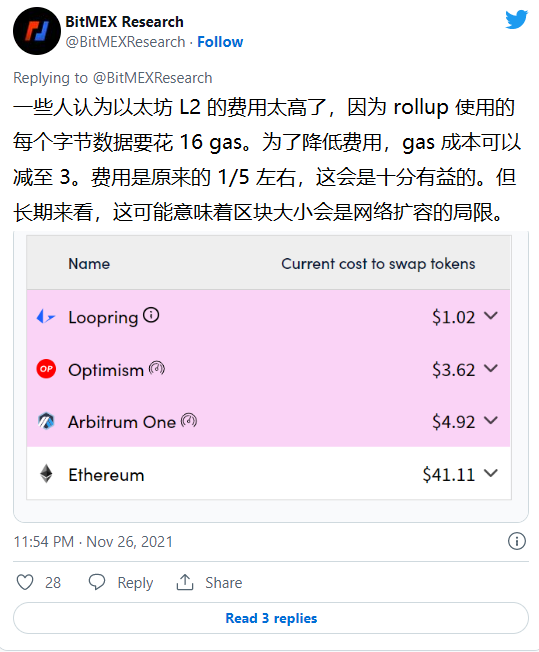
事实上,Arbitrum 和 Optimism 上的交易费依旧比 Solana 和 Polygon 等“低费用”链要高得多。
所以,是什么阻碍了这些 rollup?
了解 rollup 经济学
为了了解交易费,我们首先需要分解一笔区块链交易会产生的不同开销:
执行开销
这是网络中所有的节点执行交易并验证结果有效性所需的开销(比如,验证你确实持有要进行转账的代币)。
状态/储存开销
这是一个区块链的“数据库”更新数值的开销(比如,在代币转出之后,发出者的余额会减少而接收者的余额会增多)。
数据可用性开销
为了确保所有人都保持区块链的去信任和可验证,一条区块链就必须确保与所有网络的参与者公开共享交易的所有相关数据。
根本上,这是在保证处于这个世界的所有人都可以看见你的交易。没有这些保证,可能会出现各种攻击(所谓的数据扣留攻击)。
我们会看到,数据可用性是当前区块链的关键瓶颈之一。
Rollup:将执行转至链下
rollup 主要的进展来自于将区块链的执行和储存转至“链下”的能力,让有限的节点群体来做执行和储存。以太坊网络中的每个节点不需要执行所有的交易或储存每一次的更新数据,我们可以将这个任务委托给 rollup 的运行者。
等等,信任一个小的运行者群体?这不是中心化的吗?
好问题!
Rollup 旨在通过对各种证明类型的使用继承以太坊一样的安全性。Optimistic rollup 考虑到单个诚实个体会举报一个行为不当/作恶的定序者,让他们提交“欺诈证明”并获得奖励,而 ZK rollup 则使用零知识证明(翻译:花式加密学)来证明 L2 的链已进行了正确的更新。
数据可用性权衡
将执行迁移出主链是考虑到大幅减少执行和状态储存开销。然而,rollup 依旧必须将他们的数据发送至 L1 的链上以保证数据可用性。
基本上,rollup 的支出很便宜:L2 有执行和储存的开销,但也必须支付其发送数据至 L1 的费用。
这可以在区块链浏览器 ArbiScan 里任何交易的 “Advanced TxInfo” 标签上看到。这个交易费被分解成发送 calldata 至 L1 的开销、L2 上使用的计算开销以及 L2 储存开销。并且,几乎在所有交易中,L1 的 calldata 将会是费用的主要驱动因素。
简单地说:发送数据至 L1 是 rollup 最主要的费用瓶颈。
数据可用性的未来
当数据可用性成为了 rollup 当前的瓶颈,我们期待它会随着时间而得到缓解。
如 Proto-Danksharding 和最终的完整 Danksharding 等以太坊升级,将会大幅降低发送数据至以太坊的开销。此外,像 Celetia 等项目旨在供给独立的链,专门建来提供便宜的数据可用性。
长期来看,如 Danksharding 和 Celetia 等系统将会让数据可用性变得低廉、丰富,数据可用性的瓶颈将会转移到执行上。但是,这些解决方案需要时间才能达到成熟的程度:距离 Celetia 上线主网还有好几个月,而在以太坊通过 Proto-Danksharding 升级添加数据可用性之前,可能还需要一年以上的时间。
Calldata 压缩
数据压缩是一个比计算机更古老的领域!摩斯代码发明于在 1838 年,它是最早为人所知的数据压缩案例。但是,计算机加速了数据压缩的研究,如 Huffman 编码等算法在上世纪 50 年代发明了出来。
由于 rollup 的执行开销非常便宜,但数据可用性开销却高昂,所以这些 rollup 团队一直致力于将数据压缩算法集成至他们的协议也就不足为奇了。Optimism 已将 Zlib 的压缩算法集成至自己的 rollup 中,(阅读更多关于他们筛选算法的过程),而 Arbitrum 刚刚完成的 Nitro 升级则是使用 brotli 的压缩算法。
请注意:这个实验可能会在 Nitro 发布之前匆忙推出的,以便在未压缩的 Arbitrum 的 calldata 上进行实验。(请注意:这个实验是在 Nitro 升级发布前做的,现在升级已完成)🙂
数据压缩算法在帮助减少 calldata 的开销上无疑是十分有用工具。可是,压缩区块链交易是一项艰难的任务:通过找到共同的模式并缩短它们从而进行数据压缩工作。然而,交易中充满了地址、哈希和签名,对于这些压缩算法来说,这些数据本质上都是“随机数据”。
当开发者开始留心如何最小化他们应用程序中的 calldata ,它的开销才会真的减少。2020 年至 2021 年的天价 gas 费迫使开发者优化代码,以将执行和状态储存的开销减到最低限度。
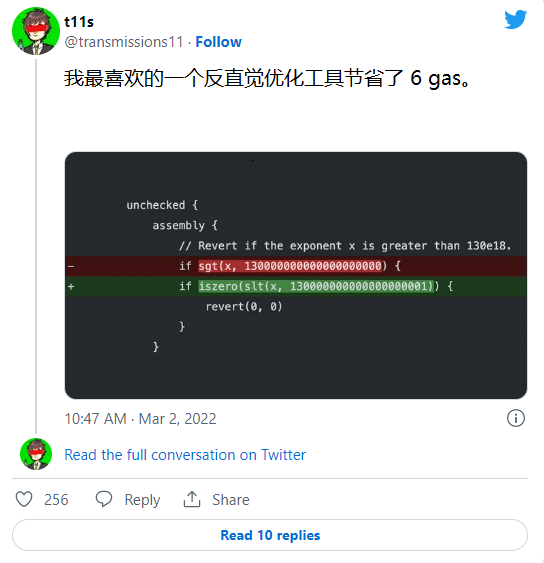
因为我们过渡到一个 L2 的世界,这里的 calldata 从最低廉的资源变成最昂贵的资源,所以开发者必须再次学习这些新的优化。
实验:我们能够将单笔代币转账压缩到什么程度
现在一起在 Arbitrum 上做个实验:我们可以将单笔代币转账需要的 calldata 压缩到什么程度?这些优化又能减少多少交易费?
我们也已经构建了一个简单的 UI,所以你可以自己试着做这个实验:
(注意:你的钱包中必须有 Arbitrum Dai、Arbitrum USDC、Arbitrum 测试网的 Dai 或者 Arbitrum 测试网的 UNI))
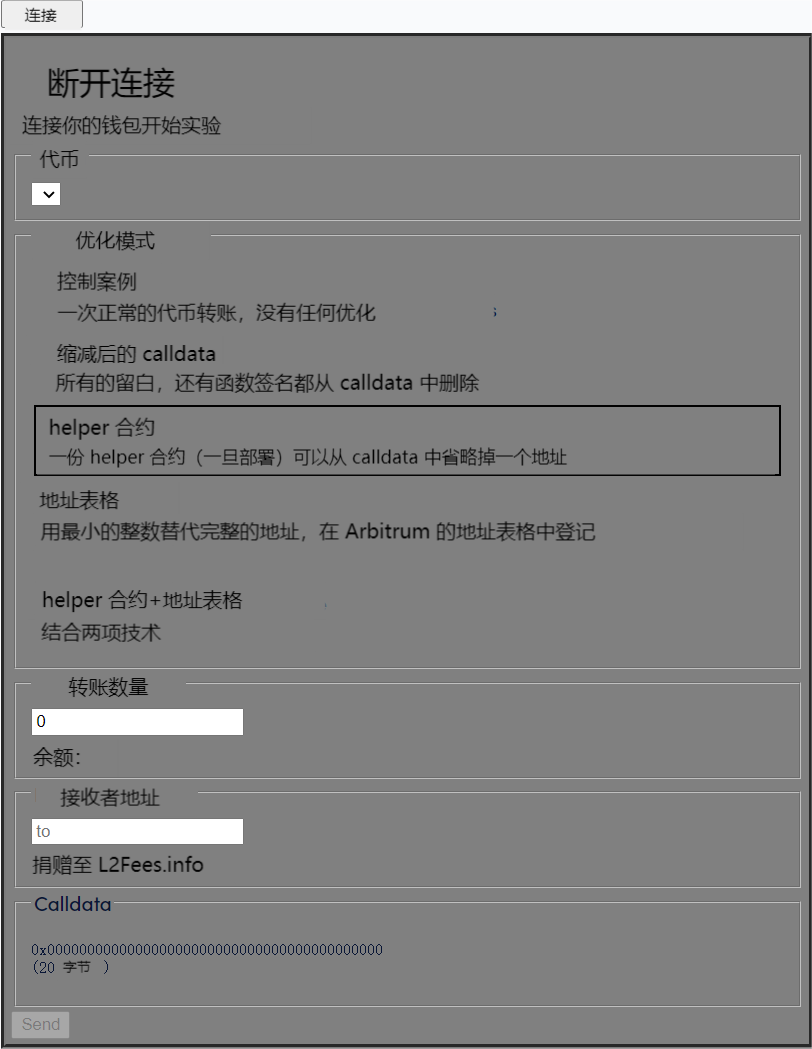
实验设计和控制案例(control case)
(译者注:控制案例即对照案例,以下所做的实验均以控制案例作为对照)
为了运行我们的实验,我们将要构建一个简单的智能合约,它会从一个交易发出者那转出 1 个代币到任何地址。
这个智能合约样本会要求用户在可以发送真实的测试交易之前发送 approve() 的交易。因为这个局限,任何用户都不会真的想要用这个系统来转账代币。但是,实验中使用的这项节约开销的技术可以适用于其他合约(比如,一个优化过的 Uniswap 路由器)。
为了开始这项实验,我们会发送一笔“控制案例”交易从而得出一个开销基准。这个交易会调用一个简单 Solidity 函数,传达代币地址、接受者地址以及代币转账数量的信息。
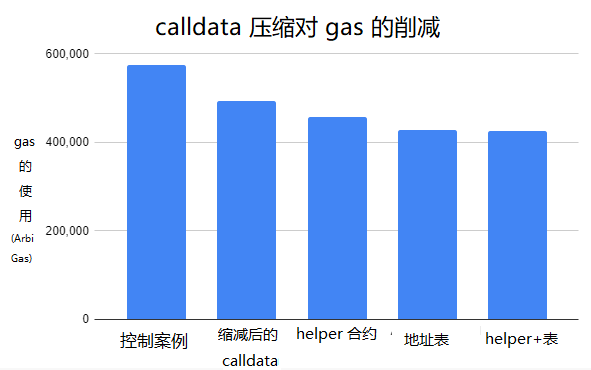
我们的测试交易使用了 576,051 ArbiGas,开销为 0.43 美元。
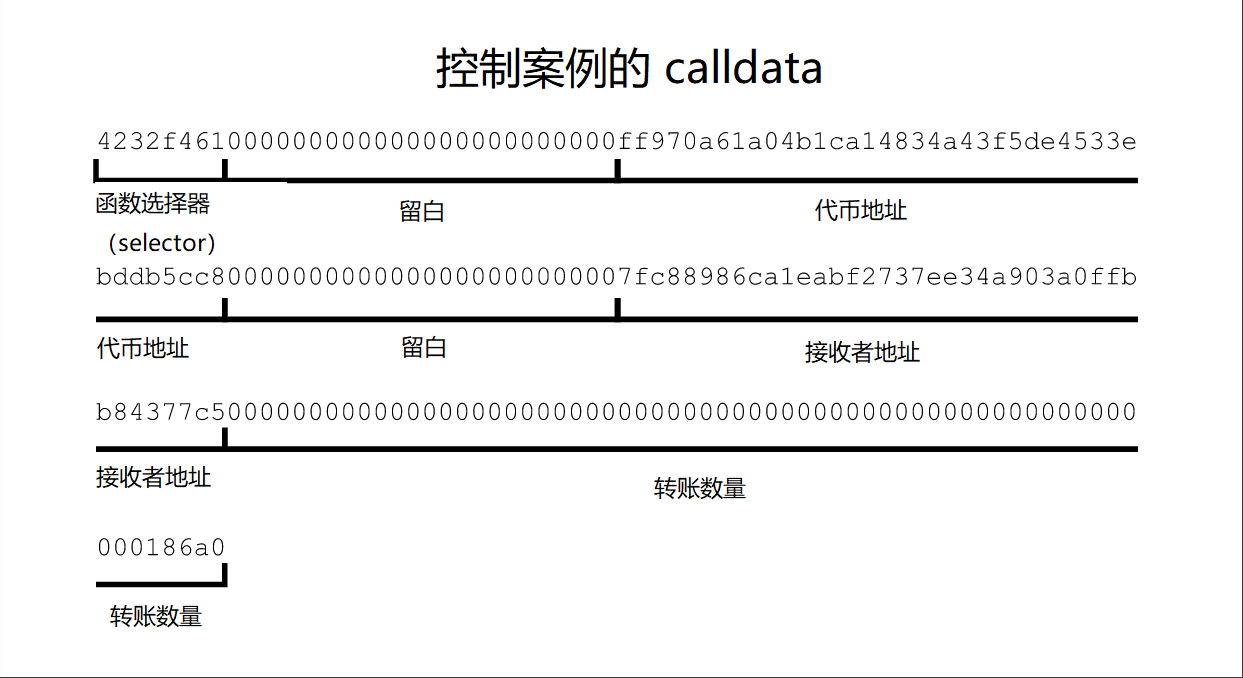
简单的 calldata 压缩
看看控制案例使用的 calldata,我们可以看到这里有很多不必要的数据可以剥离。
首先,将所有作为留白(padding)加入的 0 字节删除。0 字节比非 0 字节更便宜,但是它们还是会产生开销,所以,让我们一起删掉它们。
开头还有一个 4 字节的函数签名,这是我们想要调用的 Solidity 函数的标识符。我们可以删除这个数据,并让我们的代码简单地推断出我们想要采取什么行动。
这两个优化让我们将字节码从 100 字节删减至 43 字节。我们的测试交易使用了 494,485 gas(减少了 14%),开销为 0.37 美元。
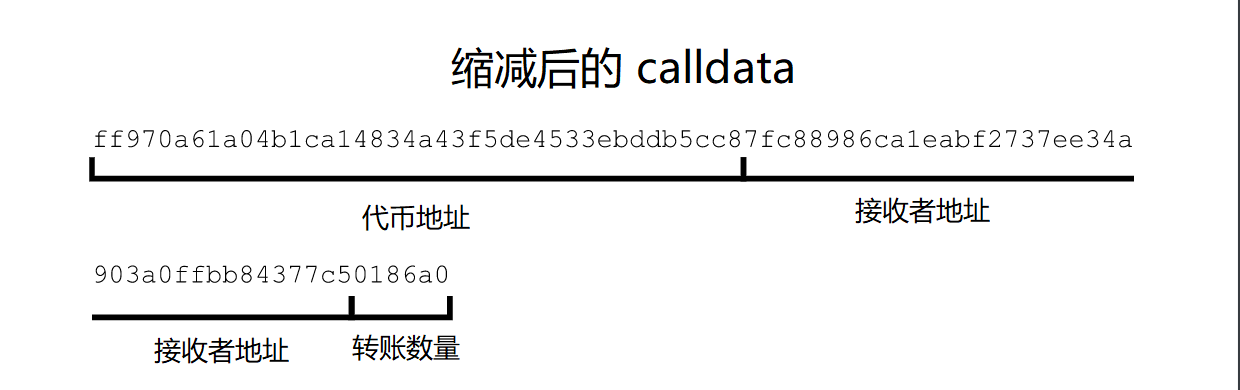
已确定的 “helper” 合约
我们 calldata 中的大部分数据由两个地址组成:一个是我们将会转出代币的地址,另一个则是转账接收者的地址。
但我们可以设想,大多数用户转着相同的几种类型的代币(WETH、Dai、USDC)。我们可以从 calldata 中删除整个代币地址的方式是为所转的代币部署一个特殊的 “helper” 合约。现在我们可以发送交易给这个 helper,完全避免了打包代币地址的需要。
这让我们可以将数据字节码减少至 23 字节。我们的测试交易使用了 457,546 gas(比控制案例减少了 21%),开销为 0.34 美元。

地址查询表
实验的上一个阶段是使用“helper 合约”以删除 calldata 中一个地址,但是还有另一个地址在我们的 calldata 中。
那么,还有其他技术可以更持续地用于“压缩”地址吗?
幸好,Arbitrum 有一个内置合约称作“Address Table Registry”(地址表登记),我们可以用它来缩减自己的 calldata。
本质上,这个合约是一本“电话簿”,将 20 字节的以太坊地址映射为简单的整数。想象一下,你的朋友有一本早期风格的电话簿:你不用将整段电话号码读出来给他们,只需要告诉他“我的号码是电话簿第 200 页的第 4 个号码”,然后让他们查找你的号码。
所以我们能做的就是制作一份合约,它会接收“地址索引”来替代完整的地址,然后在内部查找完整的地址。
通过替换“代币”地址和“接受者”地址,我们可以将 calldata 减少至 9 字节。我们的测试交易使用了 428,347 gas(比控制案例减少了 26%),开销为 0.32 美元。
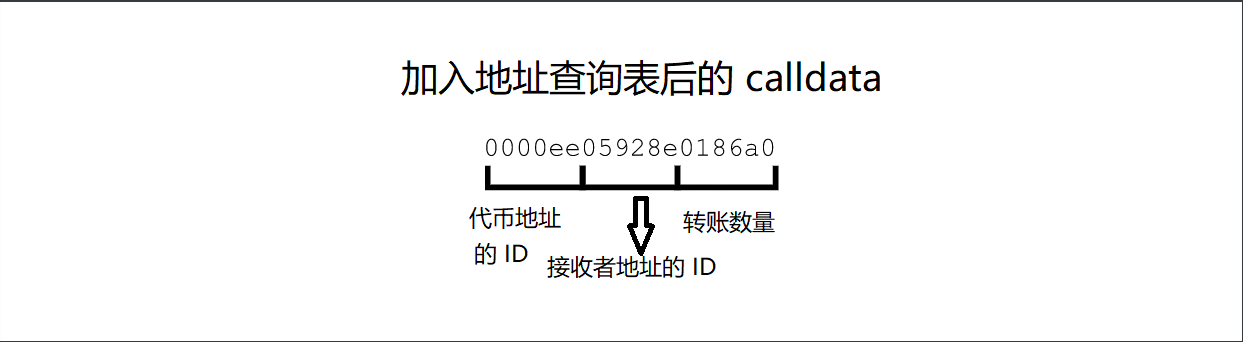
现在就结合这一切!
最后,让我们一起结合所有的技术:
- 删除补白和函数选择器
- 使用已确定的 helper 合约以删除共同的地址
- 使用 Arbitrum 的地址表缩短其他地址
总而言之,我们的 calldata 大小现在只有 6 字节!最后的测试交易使用了 426,529 gas(也是比控制案例是减少了 26%,稍微低于前一个测试案例),开销为 0.32 美元。

其他技术:有损压缩
我们所涵盖的压缩技术已经成为了“无损压缩”的案例,即压缩后输出数据包含着与所有原本输出一样的数据。
但就像照片和视频文件使用“有损压缩”算法来删除不必要信息一样,我们同样可以删除大多数案例中的不必要数据。
它的第一个例子应该是缩短数字以去除不必要的精准性。比如,一般 ERC-20 代币会精确到小数点后的 18 位数,但多数用户只在乎小数点后的 4 位数左右。我们可以构建一个合约,它会默认接受小数点后的 8 位数并乘以 10^10,并为需要更多精准度的用户提供一个辅助的函数。
同样地,日期一般显示为“自 1970 年 1 月 1 日后的秒数”(也称为 Unix 时间)。合约可以采纳分钟、小时或者天数的时间单位以减少这个日期整数的大小,它们也可以设置自己的“epoch”,比如自 2015 年 1 月 1 日起的 epoch。
要点
总结:calldata 已经从以太坊 L1 上最便宜的资源,变成以太坊 rollup 最昂贵的资源。像 Proto-Danksharding 和 Celetia 等数据可用性技术最终将会缓解这种价格瓶颈,但两个项目都还没有发布,数据可用性很可能还需要几年的时间才能变得便宜和丰富。
因此,区块链开发者需要留心他们的交易所需的 calldata 数量,因为这些会极大地影响终端用户的交易费。
这篇文章强调了很多可以用于减少 calldata 的技术,然而,随着 “optimizooors” 把焦点转向 L2,我希望会有更多技术推出。
ECN的翻译工作旨在为中国以太坊社区传递优质资讯和学习资源,文章版权归原作者所有,转载须注明原文出处以及ethereum.cn,若需长期转载,请联系eth@ecn.co进行授权。

